


What’s AWS Glue?
Are you looking to streamline your data transformation and processing tasks on AWS? Look no further than AWS Glue. In this comprehensive guide, we will walk you through everything you need to know about AWS Glue and how to make the most out of this powerful data integration service. So, let’s dive in and simplify AWS Glue for you.
Understanding AWS Glue

At its core, AWS Glue is designed to simplify your data handling processes, acting as a powerful assistant that streamlines the task of preparing, transforming, and moving your data for analysis.
This fully managed extract, transform, and load (ETL) service eradicates the need for complex coding or the management of resources typically associated with data preparation. Instead, it offers a seamless, integrated approach that allows you to focus on extracting insights from your data, rather than the underlying infrastructure.
Imagine having the capability to discover all your data across various AWS services and external sources, transforming this data in a way that’s optimized for analytics, and then loading it for immediate analysis—all with a few clicks. That’s the promise of AWS Glue. It brings a new level of efficiency and automation to ETL processes, making data more accessible and useful for businesses of all sizes.
Key Features of AWS Glue
| Feature | Description |
|---|---|
| Serverless Architecture | No server management; dynamically allocates resources; pay only for compute time used |
| ETL Capabilities | Fully managed ETL service for data preparation, transformation, and loading |
| Data Catalog | Central metadata repository; enhances data discovery and governance |
| Scripting Languages | Supports Python and Scala for custom ETL scripts |
| Integration | Seamlessly integrates with other AWS services like S3, RDS, Redshift, and external data sources |
Let’s Talk About Serverless Architecture
The heart of AWS Glue lies in its serverless architecture, which means you’re no longer bound by the constraints of server management. This aspect alone can significantly reduce the complexity and cost of your data operations. AWS Glue dynamically allocates the resources your jobs need, scales automatically to match the workload, and you only pay for the compute time you use.
But AWS Glue is more than just an ETL service. It includes the AWS Glue Data Catalog, a metadata repository that acts as a central reference for your data assets, making it easy to find and use data sources, ETL scripts, and more. This feature enhances data discovery and governance, streamlining the integration and analysis of data across diverse sources.
Additionally, AWS Glue provides built-in flexibility through its support for popular scripting languages like Python and Scala, enabling you to customize your ETL jobs for complex transformations or to integrate with a wide array of data processing frameworks. This flexibility is key for businesses that need to adapt quickly to changing data landscapes.
In essence, AWS Glue is your go-to service for ETL processes in the cloud. It’s designed to free you from the drudgery of data preparation, allowing you to leverage data for insights and decisions with greater speed and less overhead. Whether you’re consolidating data lakes, building data repositories, or optimizing data analytics, AWS Glue provides a robust, scalable solution that integrates seamlessly with the broader AWS ecosystem.

Setting Up Your AWS Glue Environment
Embarking on your journey with AWS Glue begins with establishing your own environment within this robust ETL service. This initial setup is a crucial step that paves the way for the seamless transformation and processing of your data. To set up your AWS Glue environment is simple. It is designed to integrate effortlessly with your existing AWS infrastructure and data ecosystem.
Firstly, you’ll need to navigate to the AWS Glue Console. This is your command center for all things Glue, where you’ll create and manage your ETL jobs, data catalogs, and more. If this is your first time using AWS Glue, you might need to complete some preliminary setup tasks, such as assigning the necessary IAM roles. These roles are essential for granting AWS Glue permissions to access your data in S3, RDS, Redshift, or any other supported AWS service.
Once the IAM roles are in place, the next step is to familiarize yourself with the AWS Glue Data Catalog. The Data Catalog acts as a central repository for your metadata, making it easier to manage and discover data sources. Spend some time exploring how to categorize and organize your data assets. This will streamline future tasks and ensure your ETL processes are both efficient and organized.
Steps to Set Up AWS Glue Environment
| Step | Description |
|---|---|
| Access AWS Glue Console | Navigate to the AWS Glue Console to manage ETL jobs, data catalogs, and more |
| Assign IAM Roles | Assign necessary IAM roles to grant AWS Glue permissions to access data in supported services |
| Explore Data Catalog | Familiarize with the AWS Glue Data Catalog to categorize and organize data assets |
| Define ETL Jobs | Specify source and target data stores, configure transformations, and set up job execution |
Creating AWS Glue Jobs
Creating a new AWS Glue job is your next milestone. This involves specifying your source data store, which could be located in Amazon S3, Amazon RDS, Amazon DynamoDB, or elsewhere. You’ll then define your target data store, where the transformed data will reside. AWS Glue supports a wide range of target data stores, giving you the flexibility to choose the one that best fits your project’s needs.
Configuring the ETL process is a critical phase in setting up your AWS Glue environment. Here, you’ll determine the transformations that need to be applied to your data. AWS Glue simplifies this by providing built-in transforms. However, you can write custom scripts in Python or Scala, offering you the flexibility to handle complex data transformation requirements.
Lastly, consider how your ETL jobs will be executed. AWS Glue offers the option to run jobs on demand or on a schedule. This choice will largely depend on the nature of your data processing needs. Whether your data requires frequent updates or occasional batch processing, AWS Glue can accommodate your workflow.
Creating Your First AWS Glue Job
Creating your first AWS Glue job might seem difficult, but let’s break it down together into manageable steps. Let’s transform raw data into valuable insights. Here’s how to get your first job up and running in AWS Glue.
- Step one involves selecting your source data. AWS Glue supports various sources, from Amazon S3 buckets to databases like Amazon RDS. It’s crucial to identify where your data lives and ensure AWS Glue has the permissions needed to access it. This might involve setting up the right IAM roles, as we discussed earlier, to grant AWS Glue the necessary access.
- Next, you’ll define the data targets, or where you want your processed data to be stored. This could be in another S3 bucket, a database, or a data warehouse like Amazon Redshift. The choice of your target will significantly depend on your end-use case for the data. Are you feeding a business intelligence tool, or perhaps you’re enriching a data lake?
- Following that, it’s time to configure your transformation logic. This is where AWS Glue can provide both pre-built transformation functions and the ability to script your own in Python or Scala. Whether you’re performing simple mappings or complex data cleansing, AWS Glue caters to a wide range of transformation needs. If you’re just starting out, experimenting with the built-in transforms can be a great way to familiarize yourself with the process.
and finally…
- Finally, you’ll schedule and execute your job. AWS Glue offers flexibility in job execution, allowing you to run jobs on demand or schedule them to execute at specific times. This feature is particularly useful for recurring ETL tasks, ensuring your data is always fresh and up-to-date.
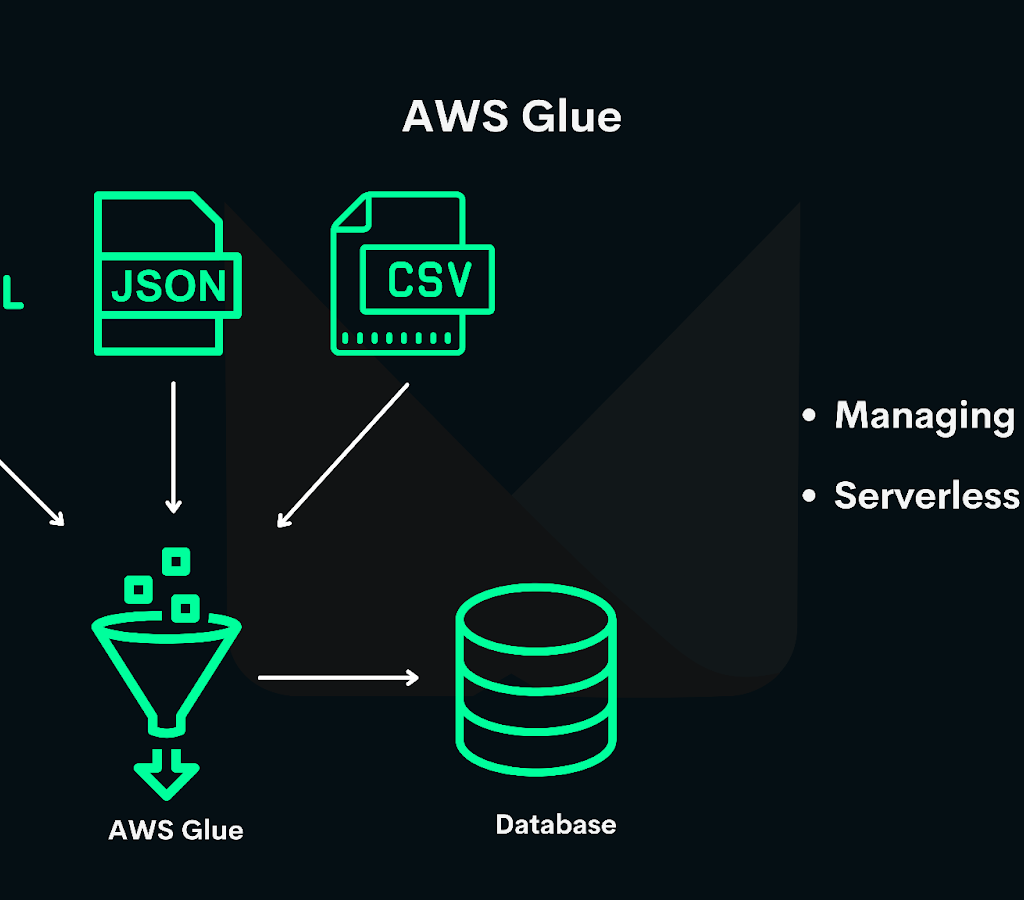
Remember, the AWS Glue console is your companion throughout this process, guiding you through each step with intuitive interfaces and helpful documentation. With each action, you’re not just running a job; you’re crafting the pathways that turn data into actionable insights.
Creating an AWS Glue Job
| Step | Description |
|---|---|
| Select Source Data | Choose data source (e.g., Amazon S3, RDS, DynamoDB) and ensure AWS Glue has access permissions |
| Define Data Targets | Specify target data store (e.g., S3 bucket, RDS, Redshift) based on end-use case |
| Configure Transformations | Use built-in transforms or write custom scripts in Python or Scala for data processing |
| Schedule and Execute Job | Set up job execution on demand or on a schedule to ensure timely data processing |
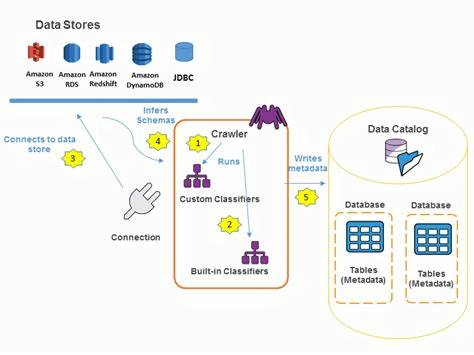
Understanding AWS Glue Data Catalog
Diving deeper into the AWS Glue universe, the Data Catalog deserves a moment in the spotlight. This feature is not just another repository; it’s the backbone of your data discovery and management within AWS Glue, enabling a smoother and more organized ETL process. But what makes the AWS Glue Data Catalog so pivotal?
At its essence, the Data Catalog serves as a central repository for all your metadata. Think of it as an organized library where every book is meticulously cataloged, except, in this case, the “books” are your data sources, ETL jobs, and transformation scripts. It’s this meticulous organization that allows for swift data discovery, accessibility, and management, making it a critical tool for data engineers and scientists alike.

One of the key benefits of the Data Catalog is its compatibility with other AWS services. It seamlessly integrates with Amazon S3, Amazon RDS, Amazon Redshift, and more, allowing you to catalog data across various AWS data stores easily. This interoperability not only saves time but also enhances your data governance practices, ensuring that your data landscape is not only comprehensible but also secure and well-managed.
But it’s not just about organizing your data. The Data Catalog also automates much of the schema discovery process. It automatically recognizes the format of your data and suggests schemas, dramatically reducing the manual effort required in classifying and categorizing data. This feature is particularly useful when dealing with large datasets, where manual cataloging can be prohibitively time-consuming.
Data Catalog Sharing
Moreover, the Data Catalog is built with sharing in mind. It enables you to share metadata across different AWS accounts, fostering collaboration within teams and across departments. This sharing capability ensures that everyone involved in data processing and analytics has access to the same information. This leads to more cohesive and efficient operations.
Embracing the Data Catalog is similar to equipping yourself with a powerful navigation tool in the vast sea of your organization’s data. It not only simplifies data management but also propels your ETL processes to new heights of efficiency and effectiveness.
Benefits of AWS Glue Data Catalog
| Benefit | Description |
|---|---|
| Central Repository | Organizes metadata for easy data discovery and management |
| Schema Discovery | Automatically recognizes data formats and suggests schemas |
| Integration | Seamlessly integrates with AWS services for streamlined data governance |
| Collaboration | Enables sharing metadata across AWS accounts to foster team collaboration |
Advanced Data Transformation with AWS Glue
Delving into the realm of AWS Glue, we uncover its true prowess when it comes to advanced data transformation. By wielding the power of Python or Scala, AWS Glue empowers you to tailor the ETL process to meet your specific data handling requirements. This segment will guide you through harnessing AWS Glue’s scripting capabilities to unlock complex data transformation with relative ease.
Imagine you’re working with data that requires intricate transformations – perhaps normalization, deduplication, or even more sophisticated operations like machine learning-based enrichments. AWS Glue’s flexible scripting environment becomes your playground. With Python or Scala at your disposal, the limitations start to fade away, allowing you to script bespoke transformations that cater to your unique data challenges.
Getting started might involve leveraging AWS Glue’s vast library of built-in functions. But as your needs evolve, so does your ability to inject custom code into your ETL jobs. Whether it’s applying a custom sorting algorithm or integrating an external data cleaning service, the script editor in AWS Glue is where your transformation logic comes to life.
Remember, the focus is not just on the transformation itself, but also on optimizing these processes for efficiency. Efficiently managing data resources, minimizing processing times, and ensuring that your scripts are well-optimized will contribute significantly to the success of your ETL jobs.

Advanced Data Transformation with AWS Glue
| Transformation Technique | Description |
|---|---|
| Built-in Transforms | Utilize AWS Glue’s library of built-in functions for common data transformations |
| Custom Scripting | Write custom transformation logic in Python or Scala for complex data processing needs |
| Optimization | Optimize scripts to minimize processing time and resource usage |
| Debugging Tools | Use AWS Glue’s debugging tools and logs for efficient troubleshooting and script refinement |
Debugging and Testing
Furthermore, AWS Glue facilitates debugging and testing of your scripts, providing a sandbox environment where you can iterate rapidly. This means that refining your transformation logic doesn’t have to be a cumbersome process. Instead, you’re equipped to streamline your development cycle, from initial script creation to final deployment.
Engaging with AWS Glue for advanced data transformations opens a world of possibilities. By leveraging scripting languages within an environment designed for flexibility, you can push the boundaries of what’s possible with your data, transforming it in ways that were once considered too complex or time-consuming.
Scheduling and Automating AWS Glue Jobs
One of the key features of AWS Glue that truly enhances its appeal is the ability to automate and schedule ETL jobs. This functionality is cool as it enables you to run data transformation and loading processes at predefined times or intervals, seamlessly fitting into your workflow without the need for manual intervention. Let’s unpack how you can use this capability to bolster your data operations, ensuring your ETL tasks are not just efficient but also impeccably timed.
Initiating the automation process begins with understanding the scheduling options AWS Glue provides. You can choose to run jobs on a trigger-based mechanism, which could be set to respond to events or on a schedule that runs at specific times. This flexibility allows you to tailor job executions precisely to your business requirements, whether that means processing data nightly to refresh your data warehouse or responding to real-time events that demand immediate data transformation.
Scheduling and Automating AWS Glue Jobs
| Scheduling Option | Description |
|---|---|
| Trigger-Based | Set jobs to run based on specific events |
| Time-Based Scheduling | Schedule jobs to run at predefined times or intervals |
| Resource Optimization | Run jobs during off-peak hours to efficiently utilize resources and reduce costs |
Setting up a schedule is straightforward, thanks to the AWS Glue Console. Here, you’ll find intuitive tools guiding you to create customizable triggers that execute jobs daily, weekly, or at any interval suited to your project’s needs. The key is to align the scheduling with your data processing requirements, ensuring that your data is always fresh, and insights derived from it are timely and relevant.
Automating AWS Glue Jobs
Moreover, automating AWS Glue jobs not only guarantees that your data workflows are consistent and reliable but also optimizes resource utilization. By scheduling jobs to run during off-peak hours, you can use computing resources efficiently, reducing costs while maintaining peak performance.
Incorporating automation and scheduling into your AWS Glue strategy empowers you to take control of your ETL processes like never before. It’s about making the service work for you, ensuring data transformation and loading are critical, well-orchestrated elements of your data strategy.
Monitoring and Debugging AWS Glue Jobs
Ensuring that your AWS Glue jobs run as expected is paramount for maintaining a smooth and efficient data pipeline. The process of monitoring and debugging these jobs might initially seem complex, but AWS Glue offers a suite of tools designed to simplify these tasks, giving you a clear view into the performance and health of your ETL processes. Let’s explore how to leverage these tools effectively, keeping your data transformations on track and minimizing downtime.
First off, AWS Glue integrates seamlessly with Amazon CloudWatch, providing real-time monitoring of your ETL jobs. This integration allows you to track metrics such as job runtime, success and failure rates, and error counts. Setting up CloudWatch alarms is a proactive measure you can take to be notified of potential issues before they escalate. For example, Configure an alarm to alert you when a job fails or its runtime significantly deviates, enabling quick responses to issues.
Monitoring and Debugging AWS Glue Jobs
| Monitoring Tool | Description |
|---|---|
| Amazon CloudWatch | Real-time monitoring of job metrics (runtime, success/failure rates, error counts) |
| Detailed Logs | Access step-by-step logs capturing job execution details and errors |
| Job Bookmark Feature | Manages job state, allowing restart from failure point, saving time and resources |
Audit Logging Capabilities
In addition to monitoring, AWS Glue equips you with detailed logs that are invaluable for debugging. These logs capture step-by-step details of job execution, including errors and stack traces, making it easier to pinpoint the root cause of failures. Accessing these logs through the AWS Management Console or programmatically via AWS SDKs allows for a flexible debugging process, tailored to your preferred workflow.
Encountering challenges and errors in data processing is par for the course, but the real test lies in efficiently diagnosing and resolving these issues. AWS Glue’s Job Bookmark feature is particularly useful in this regard, as it helps manage job state and enables you to restart jobs from the point of failure, rather than from scratch, saving time and compute resources.
By familiarizing yourself with AWS Glue’s monitoring and debugging tools, you empower yourself to maintain a robust and reliable data processing environment. Embrace these tools as part of your ETL toolkit, and you’ll navigate the waters of data integration with confidence and ease.
Best Practices for Using AWS Glue
Navigating the vast capabilities of AWS Glue with efficiency demands adherence to a set of best practices. These guidelines not only enhance the performance of your ETL jobs but also ensure that your data management strategy is both secure and cost-effective. Here are some critical best practices to keep in mind:
Firstly, meticulously manage your data sources and targets.
Using consistent organization and naming conventions across data repositories significantly reduces complexity, making it easier to automate and streamline data processing workflows.
Secondly, always leverage the AWS Glue Data Catalog. This powerful tool not only acts as a central repository for your metadata but also optimizes data discovery and governance. Utilizing it to its fullest ensures that your ETL processes are built on a solid, easily navigable foundation.
Optimizing your ETL jobs for performance is non-negotiable. This means choosing the right resources, using data partitions judiciously, and fine-tuning scripts to avoid unnecessary data shuffling. Remember, efficient code translates directly into time and cost savings.
Best Practices for Using AWS Glue
| Best Practice | Description |
|---|---|
| Data Management | Use consistent naming conventions and organization for data sources and targets |
| Leverage Data Catalog | Utilize AWS Glue Data Catalog for optimal data discovery and governance |
| Optimize ETL Jobs | Choose appropriate resources, use data partitions, and optimize scripts for performance |
| Security Measures | Implement fine-grained access controls, encrypt data, and monitor access patterns |
| Continuous Monitoring | Regularly monitor job performance and refine configurations based on insights |
Security should never be an afterthought.

Implementing fine-grained access controls, encrypting data in transit and at rest, and continuously monitoring for unusual access patterns are paramount. AWS Glue, integrated with AWS’s robust security services, makes safeguarding your data simpler and more effective.
Finally, continuously monitor job performance and iterate on your configurations. The AWS ecosystem, including CloudWatch and AWS Glue’s own monitoring features, provides deep insights into your jobs’ execution and health. Use this data to refine and evolve your ETL processes, ensuring they remain aligned with your evolving data strategy.
By following these best practices, you can fully leverage AWS Glue’s potential, turning data challenges into strategic opportunities.
Conclusion
As we wrap up our AWS Glue journey, mastering this service is crucial for efficient and streamlined data management workflows. The path we’ve covered, from setting up AWS Glue to advanced data transformations, sets the groundwork for transforming data tasks.
AWS Glue is not just a tool, but a solution designed to elevate data integration processes, enabling seamless ETL operations.
Remember, AWS Glue’s essence lies in its ability to automate, optimize, and simplify data handling processes, making data analysis more efficient and less burdensome. By leveraging the steps and practices detailed in this guide, you’re well-equipped to navigate AWS Glue, turning complex data challenges into strategic opportunities.
Embark on this adventure with confidence, knowing that AWS Glue is your ally in the quest for more efficient, reliable, and insightful data processing. The future of your data-driven decision-making looks brighter than ever with AWS Glue in your toolkit.
Share this information and please subscribe to our newsletter and website.
Also read The Impact of Artificial Intelligence Content Detection on Plagiarism – Information Technology Trends & Current News | Shift GearX





